Tuning EdgeADC Server Health Monitoring
A key feature of a load balancer is to identify and remove broken application servers from your cluster in the fastest way possible but is fastest always best?
Generally, we want to provide the best possible service to our users. Meaning that we want to remove broken servers as soon as possible and add them back when they are better as soon as possible.
To do this we need to understand the application and how it behaves, especially under stress.
The reason why this is important is that the reality of monitoring is a tradeoff between responsiveness vs false positives leading to bouncing.
If we make the health checking too fast, then a busy server may not have the time to respond and therefore it might be removed from the cluster meaning the other servers have more load in already a potentially busy time.
There are several dials to turn to get optimal health checking and this is how to set them.
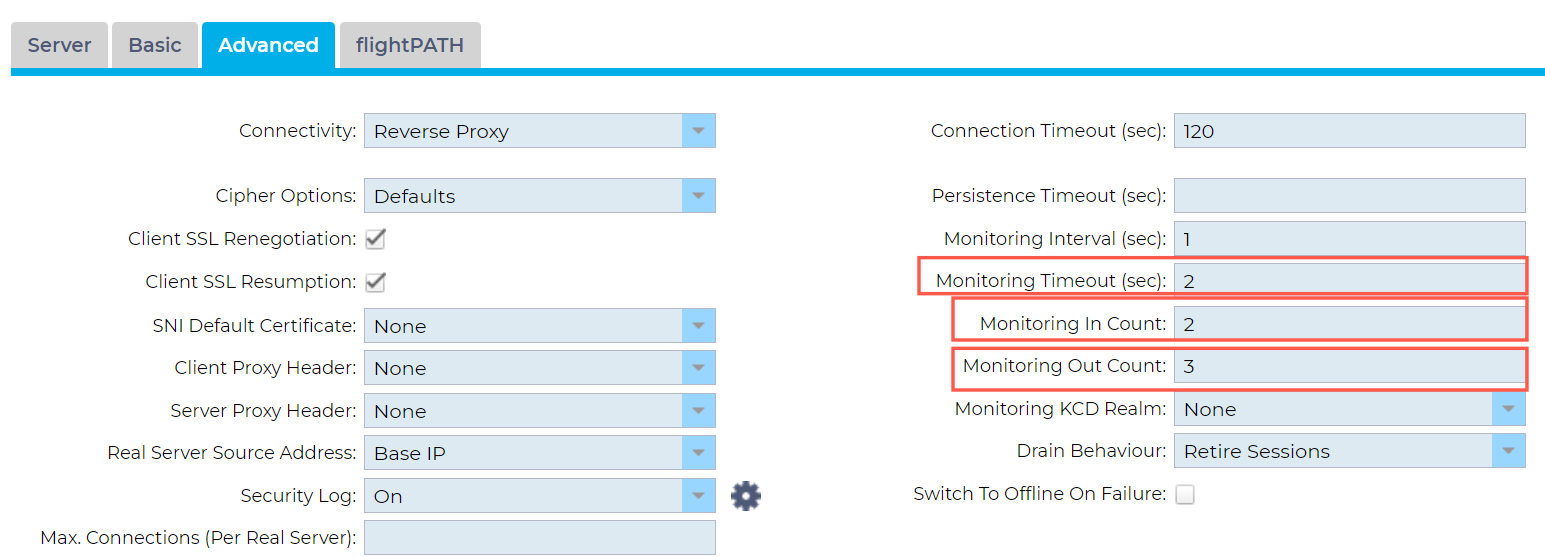
Monitoring timeout
How long should we wait to try to connect before we give up and mark it as down?
If you are using a fast-monitoring method such as TCP connect then this can be fairly low 1s
However, if you are using application-level monitoring such as HTTP get or custom monitoring this would need to be longer.
A busy web server could take up to 60s to respond, however you probably want to fail it if it is running this slowly.
Monitoring interval
How long should we wait between monitoring attempts?
Firstly, we need to make sure this is set to longer values than the monitoring timeout value or the monitoring agents will start to overlap which will lead to more complexity to interpret behaviors.
The next thing to consider is the impact of monitoring frequency changes.
What is the impact of the monitoring on the application server? For example, if you have 10 VIPS using a full HTTP monitor every second you create an additional 600 requests per minute on the server. This may be a lot depending on the server’s capacity to handle these.
For low resource monitoring such as TCP it is not such an issue.
Monitoring In Count and Out Count
This feature helps to prevent servers from bouncing in and out of service.
It is possible your application server could have a temporary “glitch” and fail a single check but it’s not severe enough to want to remove the whole server from the cluster.
Conversely once a server is removed, we want to be confident it can provide a good service before we add it back.
Generally, we suggest Out Count of 1-2, meaning it has to fail the test 1-2 times, and an In Count setting of 3 meaning it needs to pass 3 successful tests before it’s added back.